The 30-40% Problem: Why Healthcare's Over-Reliance on US-EAST-1 Is a Patient Safety Risk
Post Summary
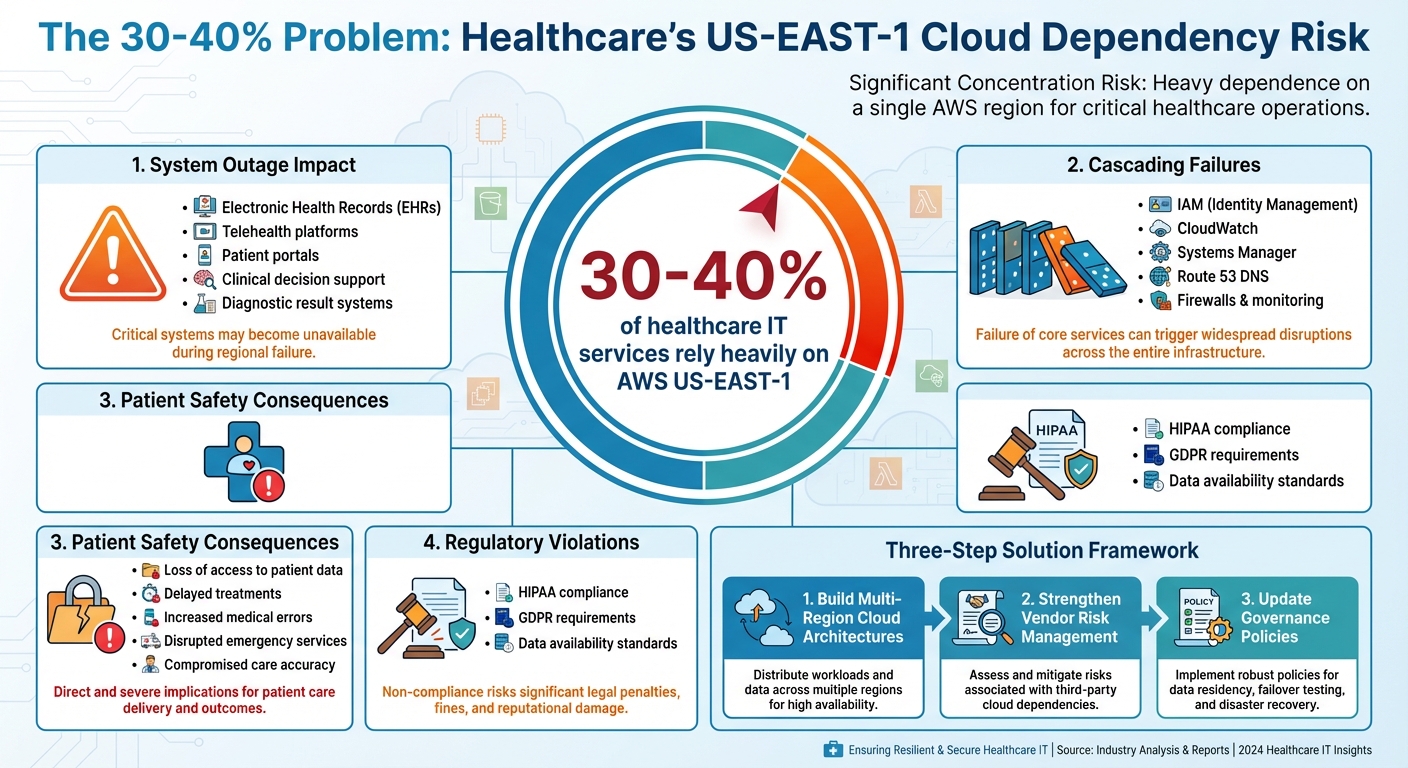
Did you know that 30-40% of healthcare IT services rely heavily on AWS US-EAST-1? This over-concentration on a single cloud region creates serious risks for patient safety. When US-EAST-1 experiences outages, critical systems like electronic health records (EHRs), telehealth platforms, and patient portals can go offline, delaying care and jeopardizing lives.
Key takeaways:
- US-EAST-1 dependency: Many healthcare providers rely on this region for hosting critical applications.
- Outage consequences: Loss of access to patient data, delayed treatments, and disruptions to telehealth services.
- Systemic risk: Shared services rooted in US-EAST-1 can cause cascading failures, even for multi-region setups.
- Regulatory concerns: Downtime can violate data availability standards under regulations like HIPAA.
To reduce these risks, healthcare organizations must:
- Build multi-region cloud architectures to avoid single points of failure.
- Strengthen vendor risk management by assessing cloud dependencies.
- Update governance policies to enforce resilient designs for critical systems.
The solution lies in creating redundancy, testing failover plans, and demanding transparency from vendors. Without these changes, patient safety remains at risk every time US-EAST-1 falters.
Healthcare's US-EAST-1 Dependency: Key Statistics and Risk Factors
The Dangers of US-EAST-1 Over-Reliance
Single-Region Dependency Creates Cascading Failures
Relying heavily on US-EAST-1 for infrastructure can expose healthcare organizations to widespread system disruptions. Many shared services, like IAM, CloudWatch, and Systems Manager, have their control planes rooted in US-EAST-1, creating vulnerabilities even in setups designed to span multiple regions [4][5][6]. When US-EAST-1 experiences issues, essential recovery operations - like creating IAM roles or updating Route 53 records - can grind to a halt, rendering backup strategies useless [6].
Traditional disaster recovery plans often focus on internal issues, such as hardware failures or power outages. But cloud outages introduce external dependencies that these plans aren’t designed to handle [4]. During US-EAST-1 outages, critical security systems - like identity management, firewalls, and monitoring tools - may only work partially, leaving healthcare providers with limited visibility and control [4]. This domino effect of failures can have serious repercussions for clinical operations.
Clinical Consequences of Cloud Outages
Cloud failures don’t just disrupt IT systems - they directly affect patient care. When critical applications go down, healthcare providers are forced to rely on less efficient backup procedures, increasing the risk of medical errors. Physicians might lose access to vital patient data, and tools like automated ordering systems, decision support platforms, and diagnostic result systems may become unavailable. This loss of access can delay or compromise the accuracy of care.
Patient-facing services, such as health portals, telehealth platforms, and clinical research systems, are also at risk. Outages can disrupt appointment scheduling, remote consultations, and ongoing studies, further impacting both patients and providers.
Regulatory and Compliance Risks
Healthcare organizations are responsible for ensuring their cloud providers meet stringent data privacy and security regulations, including HIPAA and GDPR. A single-region dependency like US-EAST-1 complicates this responsibility, as downtime can jeopardize the availability requirements mandated by these regulations [7][8].
Regulators expect organizations to design resilient systems, and relying solely on a cloud provider’s infrastructure won’t suffice as an excuse if patient care is disrupted. Building robust multi-region architectures is not just a compliance necessity - it’s a critical step in safeguarding patient safety, which lies at the heart of healthcare resilience planning.
Why Healthcare Concentrated on US-EAST-1
Technical Reasons for Cloud Centralization
US-EAST-1 has become the go-to region for healthcare organizations. As one of AWS's largest and most integral cloud regions, it offers foundational services and global features that aren’t available elsewhere[9]. It also hosts the control planes for several key AWS services like IAM, AWS Organizations, and Route 53 Private DNS[6]. In the early days of cloud computing, many healthcare vendors deployed their primary applications here, leading to a heavy concentration of infrastructure in this region. While this centralization simplified initial deployments, it also introduced vulnerabilities that now pose significant challenges for risk management.
Gaps in Healthcare IT Risk Management
The reliance on US-EAST-1 has exposed critical weaknesses in healthcare IT risk planning. Concentrating services in one region has created a systemic vulnerability, as noted by Forrester:
"Concentration risk - a dangerously powerful yet routinely overlooked systemic risk - arises when so many companies across all industries become dependent on a single cloud provider and, more pertinently, a single region covered by that vendor" [1].
Healthcare organizations often prioritized cost and convenience over resilient design[1], neglecting to fully address the unique risks associated with cloud dependency. Traditional continuity plans frequently underestimated how external cloud services could impact operations[4]. Todd Renner, Senior Managing Director in Cybersecurity at FTI Consulting, highlighted this gap:
"IT leaders have trusted providers to ensure they are meeting availability requirements" [4].
This misplaced trust stems from a misunderstanding of the shared responsibility model, where providers manage the infrastructure, but customers are responsible for application resilience and architecture[1][2]. Additionally, third-party risk management programs often focused too narrowly on compliance, missing broader operational risks. As one analysis put it:
"If a third-party risk management (TPRM) program is overly focused on compliance, you'll likely miss significant events like this one that impact even compliant vendors" [1].
Service Level Agreements (SLAs) also offered limited recourse - often providing minimal credits that fell far short of covering damages from multi-hour outages. Many organizations failed to negotiate stronger terms for these agreements[2].
Measuring Your US-EAST-1 Exposure
To understand how dependent your organization is on US-EAST-1, start by differentiating between control planes and data planes. Recovery plans that rely on control plane operations in this region are particularly vulnerable during outages[6]. Begin by auditing your failover procedures and creating a detailed inventory of critical resources like ELBs, RDS instances, S3 buckets, Route 53 DNS records, and IAM users. Review vendor contracts to identify dependencies on US-EAST-1[6].
It’s also critical to determine which resources are pre-provisioned and which would require control plane access during recovery[6]. For large enterprises, untangling these dependencies within complex cloud architectures can be daunting but is essential for building resilience[3]. This kind of thorough inventory work is a necessary step to mitigate risks tied to US-EAST-1.
How to Reduce US-EAST-1 Dependency Risks
Implementing Multi-Region Cloud Architectures
For healthcare applications like electronic health records (EHRs), patient monitoring, and decision support systems, adopting multi-region architectures can be a game-changer. By spreading infrastructure across multiple regions, you can ensure these critical systems remain operational even when one region, such as US-EAST-1, faces an outage[11]. The key is to design systems that stay functional without requiring last-minute provisioning or reconfiguration during a crisis[10][6].
Start by determining which applications need an active-active setup - where systems run simultaneously in multiple regions with automatic traffic routing - and which can operate with an active-passive model, where a secondary region remains on standby until needed. Minimizing reliance on control plane operations, especially those tied to US-EAST-1, is vital. Pre-provisioning resources in alternate regions can save valuable time during a recovery scenario.
Regular failover testing is equally important. By simulating US-EAST-1 outages, you can gauge recovery times and identify weak points that might not be obvious from documentation alone. While building technical resilience is crucial, combining it with strong vendor risk management practices further reduces exposure to dependency risks.
Strengthening Vendor Risk Management
Vendor transparency is non-negotiable when it comes to cloud architecture. Even the most reliable applications can fail if their core infrastructure is tied to a single region. Over-reliance on US-EAST-1 amplifies these risks[12][13].
Tools like Censinet RiskOps can help healthcare organizations evaluate vendor resilience by mapping dependencies during risk assessments. When vetting vendors, ask direct questions: Which AWS regions host your production systems? What percentage of your operations depend on US-EAST-1? How do you handle regional outages, and what is your actual recovery time compared to your SLA promises?
These answers allow you to create a clear dependency map, highlighting which vendors share similar infrastructure risks. This visibility helps prioritize diversification efforts and negotiate stronger contracts that address these vulnerabilities.
Updating Governance and Policy Frameworks
Governance policies must evolve to address today’s operational risks. Vendor contracts should allocate risk based on the criticality of their services[2]. Since SLA credits rarely cover the costs of disrupted patient care, contracts should clearly define recovery expectations and hold vendors accountable.
Require vendors to disclose their cloud architecture, including regional dependencies, during both the initial due diligence process and ongoing reviews. Embedding these requirements into procurement ensures transparency becomes standard practice. Additionally, boards should regularly review reports on cloud concentration risks, treating them with the same level of urgency as cybersecurity or financial risks.
Policies should also outline when multi-region architecture is mandatory. Systems tied to life-critical functions - like patient monitoring, emergency care, or medication administration - must have geographic redundancy as a default requirement. For any high-risk, single-region deployments, ensure executive approval is documented and secured.
sbb-itb-535baee
Maintaining Long-Term Oversight of Cloud Risks
Creating Key Risk Indicators (KRIs)
When it comes to effective oversight, tracking the right metrics is essential. For example, keep an eye on the percentage of critical workflows reliant on US-EAST-1 - this single metric can reveal just how exposed your operations are. Another key metric is the time since your last failover test. Why? Because a recovery plan that hasn’t been tested often won’t hold up when you need it most. Additionally, count the number of single points of failure within US-EAST-1, and assess how well your disaster recovery drills meet your Recovery Time Objective (RTO) and Recovery Point Objective (RPO) targets.
Beyond operational metrics, monitor AWS Config compliance, unauthorized IAM changes, failed login attempts, and unauthorized S3 access. These indicators help you catch potential security risks early. As Kayne McGladrey, CISSP, pointed out after the October 2025 AWS US-EAST-1 outage that disrupted organizations like Lloyds Bank, HMRC, and Coinbase: "Resilience cannot simply be bought; it must be built, tested, and diversified" [12].
Connecting Cloud Resilience to Patient Safety Programs
Cloud risks are not just an IT problem - they have real-world implications, especially in healthcare. Metrics that measure cloud performance should be directly linked to patient safety initiatives. For instance, when cloud failures disrupt workflows, delay treatments, or impact emergency services, they pose risks as serious as any clinical system failure [14].
To address this, patient safety committees need to include cloud concentration risks in their reviews, just as they would any other critical safety metric. Integrating cloud resilience into root cause analyses ensures that leadership understands the operational risks - like a DNS configuration issue in US-EAST-1 - and their potential impact on patient care. This approach naturally leads to tools and processes that make risk oversight more efficient and actionable.
Using Censinet for Continuous Risk Management
Censinet RiskOps offers a centralized platform to monitor cloud resilience metrics across your vendor ecosystem. By automating vendor assessments and mapping dependencies, it helps identify shared exposures, such as those tied to US-EAST-1. Censinet’s AI simplifies the process by streamlining questionnaires and summarizing vendor evidence, allowing your team to focus on addressing risks rather than getting bogged down in manual reviews.
The platform’s command center provides a real-time view of cloud concentration risks, ensuring that critical findings reach the right stakeholders. Think of it as an "air traffic control" system for governance - helping your team detect emerging risks early and maintain continuous oversight without being overwhelmed by manual tracking.
Conclusion: Solving the 30–40% Problem
The fact that 30-40% of healthcare workloads are concentrated in AWS US-EAST-1 isn't just a technical challenge - it poses a serious risk to patient safety. When cloud outages occur, they can disrupt hospital workflows, delay critical care, hinder emergency services, and jeopardize clinical decision-making [14]. This centralized cloud dependency is a cyber threat that many healthcare organizations have already faced firsthand [15][16].
To address these challenges, operational resilience must become a priority. Organizations should implement multi-region architectures, enhance vendor risk management processes, and revise governance frameworks to reduce the risks tied to cloud concentration [1]. Cloud resilience isn't someone else's responsibility - healthcare providers need to actively design, test, and diversify these systems within their own operations.
Continuous visibility and oversight are equally important. This includes monitoring key risk indicators, linking cloud resilience metrics directly to patient safety initiatives, and keeping a real-time view of vendor dependencies. Tools like Censinet RiskOps can help by providing centralized monitoring of cloud dependencies and ensuring that critical insights are shared with the right stakeholders without delay.
FAQs
What are the risks of healthcare organizations relying heavily on the US-EAST-1 cloud region?
Over-relying on the US-EAST-1 cloud region presents serious risks for healthcare organizations, especially during regional outages. When these disruptions occur, they can directly affect critical systems like electronic health records (EHRs), telemedicine platforms, and Internet of Medical Things (IoMT) devices - all of which are essential for patient care and safety.
Even organizations using multi-availability zone (Multi-AZ) configurations aren't immune to region-wide failures. Such incidents can lead to widespread service interruptions, forcing healthcare providers to fall back on manual processes. This shift not only increases the chance of errors but can also delay treatments and jeopardize patient outcomes.
To reduce these risks, healthcare IT teams need to prioritize strategies like diversification, redundancy planning, and conducting comprehensive risk assessments. Tailoring these approaches to the unique demands of healthcare systems can help ensure continuity and protect patient care during unexpected disruptions.
What steps can healthcare organizations take to implement a reliable multi-region cloud strategy?
To establish a dependable multi-region cloud strategy, healthcare organizations should spread workloads across various cloud regions. This approach minimizes dependency on a single location and helps maintain services even during unexpected disruptions. Deployment models like active-active or active-passive can be used to ensure smooth failover and reduce downtime.
Critical steps include setting up strong data replication systems and disaster recovery plans. Tools such as virtual routers and load balancers are vital for keeping connections stable. Additionally, organizations must meet regional compliance and security standards, routinely test failover procedures, and implement automated monitoring to quickly identify and address issues. These practices help maintain uninterrupted operations and protect patient safety, even during outages.
How can healthcare organizations reduce risks associated with cloud dependencies?
Healthcare organizations can reduce risks associated with cloud dependencies by spreading their reliance across multiple cloud providers and implementing multi-region architectures. This approach avoids creating single points of failure. Adding layers of redundancy to systems and keeping offline capabilities ready ensures operations can continue even during unexpected disruptions. Conducting regular risk assessments helps pinpoint vulnerabilities, while robust vendor management practices ensure adherence to essential security standards like HIPAA and NIST. Together, these measures enhance system resilience and safeguard patient safety.
Related Blog Posts
- When Multi-AZ Isn't Enough: What the AWS US-EAST-1 Failure Taught Us About True Resilience
- 7 Hours Down, Millions Affected: Inside the AWS Outage That Broke Healthcare's Digital Backbone
- The AWS Outage Exposed Cloud Vulnerabilities - What It Means for Healthcare Business Continuity
- Cloud SLAs vs. Reality: Why 99.99% Uptime Promises Failed Healthcare on October 20

